认识 LangTest、LangGraph、LangChain、LangSmith 和 LlamaIndex 以及他们之间的关系
同一生态下的 LangTest、LangChain、LangGraph 和 LangSmith 这几兄弟的区别。如果把开发 AI 应用比作盖房子,它们的角色是这样的:
-
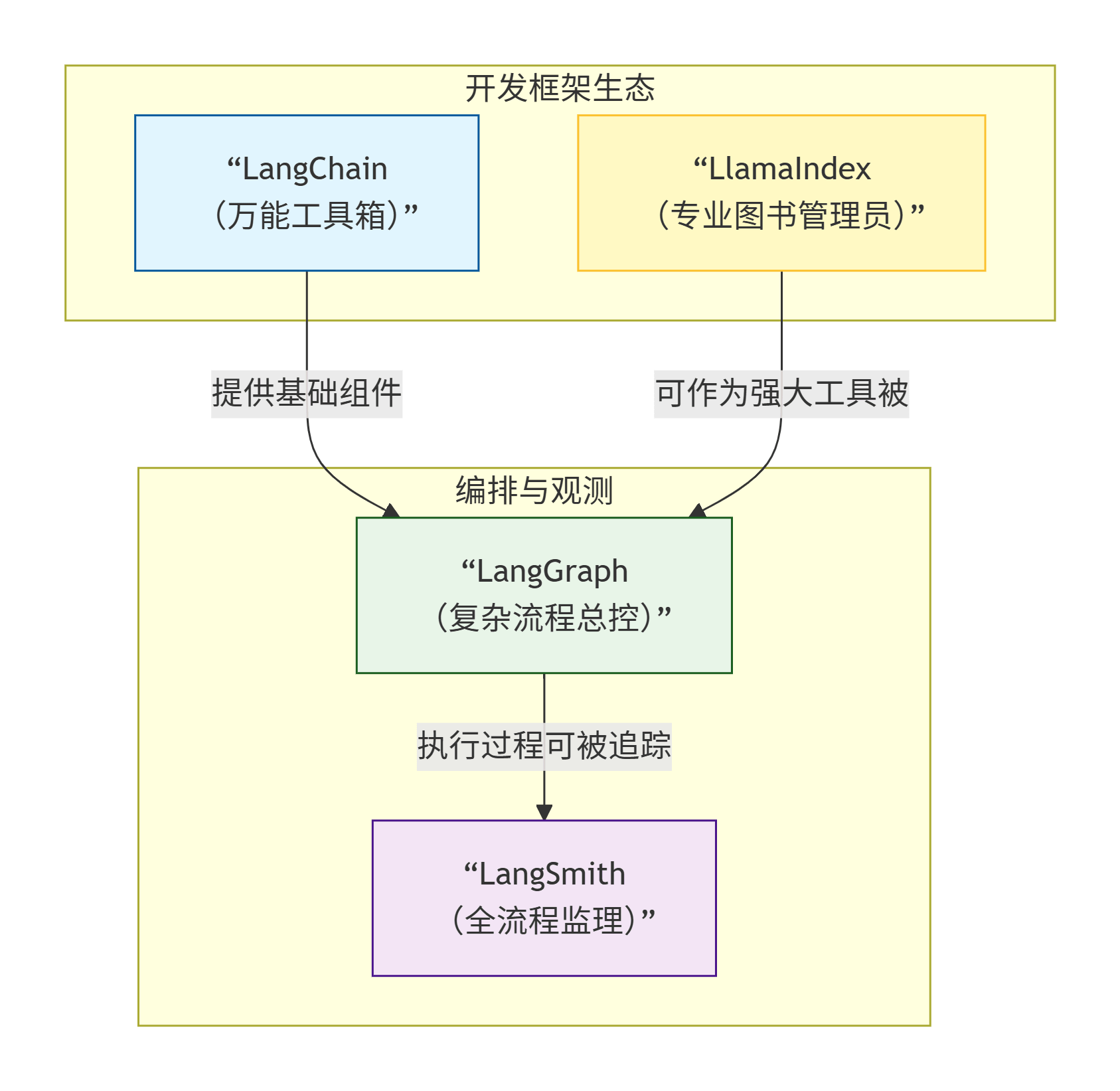
LangChain:是你的“工具库和建材超市”,提供从模型调用、文档加载到提示词模板的各种预制件,让你能快速把房子搭起来 。
-
LangGraph:是“总施工图和水电管网”,专门用来设计复杂的内部流转路径(比如多步推理、循环、条件分支),确保各个房间(功能)之间逻辑清晰、状态可控 。
-
LangSmith:则是“工程监理和物业系统”,全程盯着施工质量(调试)、记录水电读数(监控),并在房子交付后帮你持续优化维护 。
-
LangTest:则是“抗震设防与竣工验收”,模拟地震(模型的安全性、稳健性))、防火(偏见),确保房子不会因为外力一推就倒。
🤗 三者之间核心区别
| 维度 | LangChain | LangGraph | LangSmith |
|---|---|---|---|
| 核心定位 | 应用开发框架 | 智能体编排引擎 | 全生命周期平台 |
| 主要目标 | 提供标准化组件,快速构建LLM应用 | 构建复杂、有状态、可控的智能体工作流 | 调试、监控、测试、优化LLM应用 |
| 工作流模型 | 链式(线性/分支),通过LCEL语言编排 | 图状(有环/循环),由节点和边组成的状态机 | 观测、分析和评估的闭环流程 |
| 核心抽象 | Chain(链), Agent(智能体), Tool(工具), Memory(记忆) |
StateGraph(状态图), Node(节点), Edge(边), Checkpoint(检查点) |
Trace(追踪), Run(运行), Dataset(数据集), Experiment(实验) |
| 状态管理 | 简单,依赖Memory组件传递上下文 |
强大且持久化,有中央状态,支持中断、恢复和时间旅行 | 关注运行时的状态记录和分析 |
| 适用场景 | RAG、文档问答、简单的聊天机器人、文本处理 | 多步推理的复杂Agent、多智能体协作、需人工介入的流程、长期运行任务 | 生产环境应用监控、性能瓶颈分析、回归测试、提示词调优 |
| 与另外两者的关系 | 为LangGraph提供基础组件(模型、工具、检索器) | 可以调用LangChain的组件,其执行过程可被LangSmith追踪 | 监控LangChain和LangGraph应用的运行情况 |
🧱 LangChain:快速上手的“工具库”
它是你进入LangChain生态的第一站。当你需要快速实现一个标准的、线性的LLM应用时,比如做一个内部知识库问答机器人(RAG),LangChain是最佳选择。它提供了大量封装好的组件(如文档加载器、各种模型的接口),让你用很少的代码就能把想法变成现实 。
🕸️ LangGraph:复杂流程的“总控图”
当你的应用变复杂,比如需要让AI反复调用多个工具、根据结果进行多步推理、或者嵌入一个人工审批环节时,LangChain的线性模型就不够用了。LangGraph通过“图”的方式来定义流程,每个节点是一个操作,每条边是流转逻辑。这种设计让它能完美支持循环、分支和复杂的状态管理,是实现复杂AI Agent的首选框架 。
🔬 LangSmith:生产落地的“护航舰”
当应用开发完成并上线后,如何确保它稳定可靠?LangSmith就是为此而生的。它是一个配套的商业化平台,你可以把它理解为AI应用的可观测性工具。它能记录每一次运行的详细轨迹,帮你调试为什么某次回答出了问题;也可以评估不同Prompt对结果的影响,或者建立自动化测试来防止模型更新导致效果下降。
🧪 LangTest:压力测试仪
它与上面三者(通常由 LangChain 团队开发)血缘关系稍远,但功能互补。
-
它专注于合规性和鲁棒性。如果你担心模型会说出歧视性言论,或者被轻易“洗脑”(注入攻击),LangTest 可以自动生成成千上万个测试用例来“拷问”你的应用。
之前把 LangChain 比作“工具库和建材超市”,LangGraph 比作“总施工图”,LangSmith 比作“工程监理”, LangTest 比作“竣备验收”。在这个比喻里,LlamaIndex 就是一个功能极其强大的“专业图书管理员”。它的核心目标非常专注且明确:让你能轻松地与自己的私有数据(文档、数据库等)进行“对话”。
👩💻 LlamaIndex:专注于“数据”的专家
LlamaIndex 的诞生就是为了解决一个问题:如何让大模型更好地理解和利用你的私有数据 。它的专长非常突出:
-
数据连接器:它拥有一个名为
LlamaHub的巨大仓库,提供了数百种现成的“数据加载器”,可以让你轻松地从各种地方读取数据,比如 PDF、网页、数据库(SQL)、Notion、Google Drive 等 。 -
高级索引与检索:LlamaIndex 提供了非常丰富的索引策略(不止是简单的向量索引),并对检索过程进行了深度优化,例如内置了混合检索(结合关键词和语义)、重排序(让最相关的结果排在前面)等功能,旨在从你的数据中捞出最“精华”的部分 。
-
解析复杂文档:它还提供了一个叫
LlamaParse的工具,专门用来解析格式复杂的文档(比如带有表格、图表的PDF),能很好地保留文档的原始结构和信息,这对于企业级知识库来说至关重要
🆚 LlamaIndex vs. LangChain:分工不同,但可互补
LlamaIndex 和 LangChain 是目前最主流的两个AI应用框架,它们的关系更像是专业工具和瑞士军刀 。
| 维度 | LlamaIndex (专业图书管理员) | LangChain (万能工具箱) |
|---|---|---|
| 核心定位 | 以数据为中心的框架,专注于检索增强生成 (RAG) 。 | 以编排为中心的框架,提供构建LLM应用的各种通用组件 。 |
| 专长领域 | 数据检索质量。在文档索引、查询、评估方面做得非常深入,开箱即用 。 | 流程与Agent。擅长将多个步骤(如调用模型、使用工具)链接起来,构建复杂的推理逻辑 。 |
| 与LangGraph关系 | 本身是一个独立框架,但其“检索”能力可作为强大工具被LangGraph调用。 | 是LangGraph的基础,为它提供核心的模型、工具等基础组件 。 |
| 最佳场景 | 企业内部知识库问答、需要对大量文档进行精确检索和总结的场景 。 | 需要调用外部工具(如搜索引擎、API)的智能Agent、复杂的多步推理流程 。 |
如果你的核心需求是“从一堆文档里找出最准确的答案”,LlamaIndex 可能是更直接的选择。但如果你需要构建一个能自己上网查资料、然后调用计算器、最后发送一封邮件的复杂Agent,LangChain/LangGraph 的组合会更强大。
🤝 LlamaIndex 与 LangGraph/LangChain 的关系:互相成就
它们并不是非此即彼的竞争关系,反而可以强强联合 。
-
LlamaIndex 为 LangGraph 所用:你可以把整个 LlamaIndex 强大的检索查询引擎,当作一个功能极其强大的“工具箱”,集成到你的 LangGraph 工作流中 。
-
想象一下:你用 LangGraph 构建了一个“金融研报分析Agent”。当用户提问“对比一下A公司和B公司去年的ROE”时,LangGraph 负责整体的任务规划和调度,但它具体去翻财报、找数据时,就可以调用一个由 LlamaIndex 封装好的“财报知识库查询工具”,把专业的事交给专业的“图书管理员” 。
-
-
LangChain 为 LlamaIndex 提供基础:反过来,LlamaIndex 内部也常常借用 LangChain 的生态。比如,你可以用 LlamaIndex 来做索引,然后用 LangChain 的模型和工具来执行后续的生成或动作 。
💡 总结一下
-
LangChain = 万能工具箱(给你所有零件,让你自己组装)。
-
LangGraph = 智能施工图(教你如何用零件搭建一个能自动运转的复杂机器)。
-
LangSmith = 工程监理(盯着机器运行,记录问题,帮你优化)。
-
LlamaIndex = 专业图书管理员(最懂怎么从海量书里给你找到最需要的那段话)。
-
LangTest = 竣备验收(能不能拿到你最需要的那段话和检查你最需要的那段话是不是合理的)
在实际项目中,它们完全可以共存。你既可以用 LlamaIndex 来搭建一个高质量的知识库,也可以用 LangGraph 来编排一个智能Agent去调用这个知识库,最后用 LangSmith 来监控整个流程的效果 。事实上,一些企业平台(如 UiPath)已经开始同时支持 LangGraph 和 LlamaIndex 的 SDK,正是看中它们这种互补关系 。

文章部分资料可能来源于网络,如有侵权请告知删除。谢谢!
前一篇: RAG 向量数据库的认识和举例
下一篇: llama.cpp 和 ollama 的联系和区别
关于作者
Zhuoyuebiji ( 广东·深圳 )
🚩成长的时候,能帮有需要的你
我是 卓越笔记,软件测试工作者,热爱互联网,喜欢琢磨,遇到问题就一定要找到答案。我的博客主要记录学习中遇到的知识点和遇到的问题及问题的解决方法。欢迎同样热爱互联网的小伙伴们交换友链,一起探索互联网的世界 😊